모델 개발, 서비스 설계, 배포 운영을 한 흐름으로 연결해
AI 기능이 실제 사용자 경험 안에서 작동하도록 만듭니다.
Education
생명과학과 심화전공
의료인공지능 마이크로전공
Bootcamp
생성형 AI 과정 수료
Core Strength

TechTree는 Agent 시스템,
미야옹은 모델/데이터 엔지니어링,
Sysmed는 도메인 데이터 이해력을 보여줍니다.
TechTree
AI Agent 서비스 설계와 운영
미야옹
도메인 특화 sLLM 개발과 모델 서빙
Sysmed
의료 데이터 이해와 연구 데이터 처리
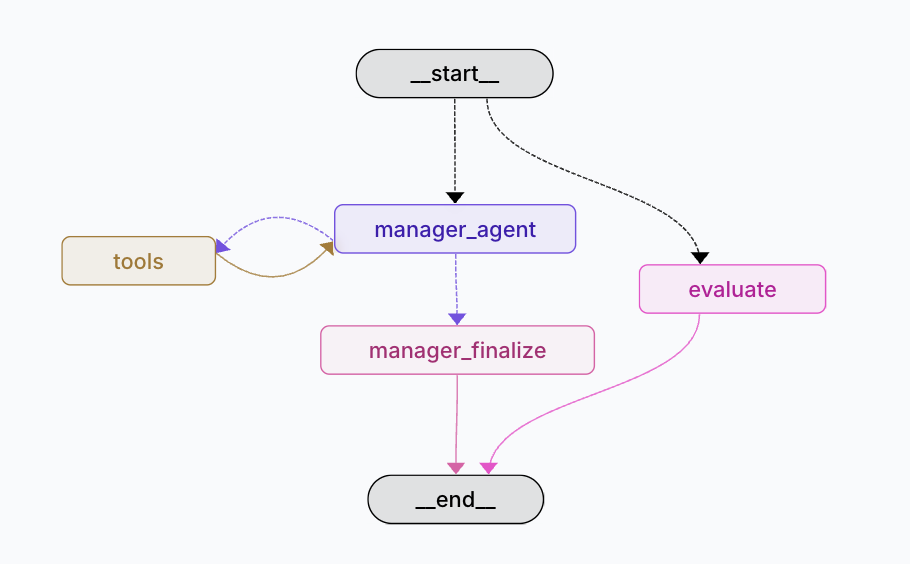
AI Interview
Agent System
이력서와 채용 공고를 바탕으로 실시간 음성 면접을 진행하고, 대화 근거 기반 평가 리포트까지 생성하는 AI 면접 서비스입니다.
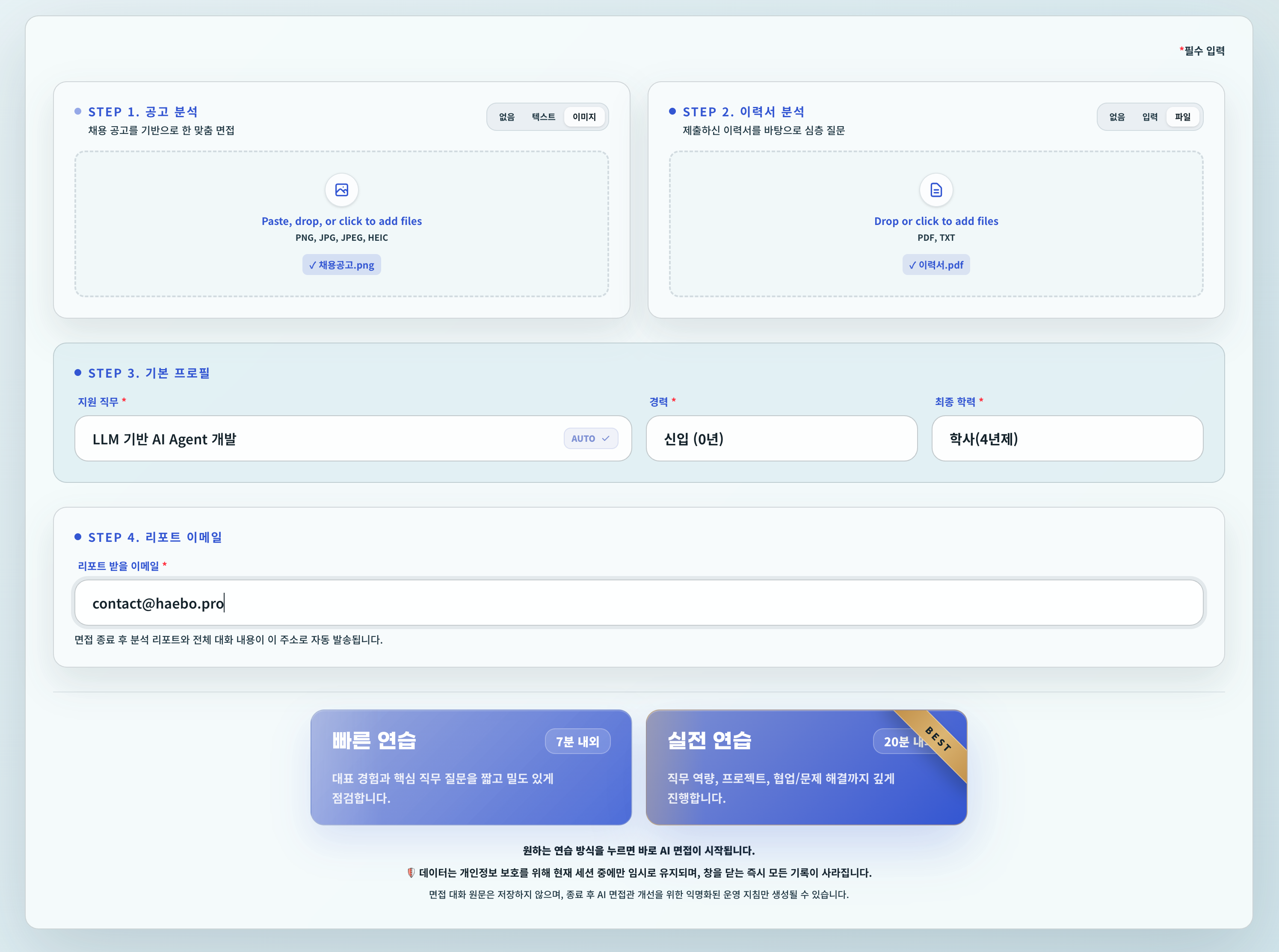
이력서와 지원 공고 입력을 기반으로
면접 질문과 평가 리포트의 근거를
만듭니다.
이력서/PDF 입력
지원자의 경험과 기술 스택을 면접 질문 생성의 기본 컨텍스트로 사용합니다.
지원 공고 기반 맥락
직무, 경력, 학력, 채용 공고를 함께 분석해 지원 포지션에 맞는 질문을 구성합니다.
완료 후 리포트
면접 대화 내용을 기반으로 평가를 진행하고 이메일 리포트를 발송합니다.
브라우저에서 실시간 AI 모델을 직접 연결하고,
FastAPI는 제어를, LangGraph는 상태 흐름을 관리합니다.

면접 중 지원자가 생각하는 시간을
'답변 종료'로 오해하지 않으려면?
"일반적인 VAD(음성 감지) 방식은 지원자가 답변을 잠시 생각하며 침묵하는 순간을 '답변 종료'로 오인하여 흐름이 끊기는 한계가 있습니다."
선택한 해결책
- ✓ 브라우저와 OpenAI Realtime API를 WebRTC로 직접 연결
- ✓ FastAPI는 client secret 발급과 세션 제어에 집중
- ✓ 스페이스바를 누르고 있는 동안 답변하고, 떼면 답변이 종료되는 Push-to-Talk 방식
실시간 대화와 복잡한 에이전트 로직을
어떻게 충돌 없이 공존시킬 것인가?
"실시간 대화 루프에 LangGraph가 개입하면 매 대화마다 치명적인 통신 부하가 발생합니다. 이를 막기 위해 실시간 엔진은 사전 주입된 컨텍스트로만 초저지연 대화를 진행하고, 생성된 스크립트는 종료 후 에이전트에 비동기로 전달하여 병목을 원천 차단했습니다."
단계별 책임 분리
면접 리포트가 그럴듯한 생성문이 아니라
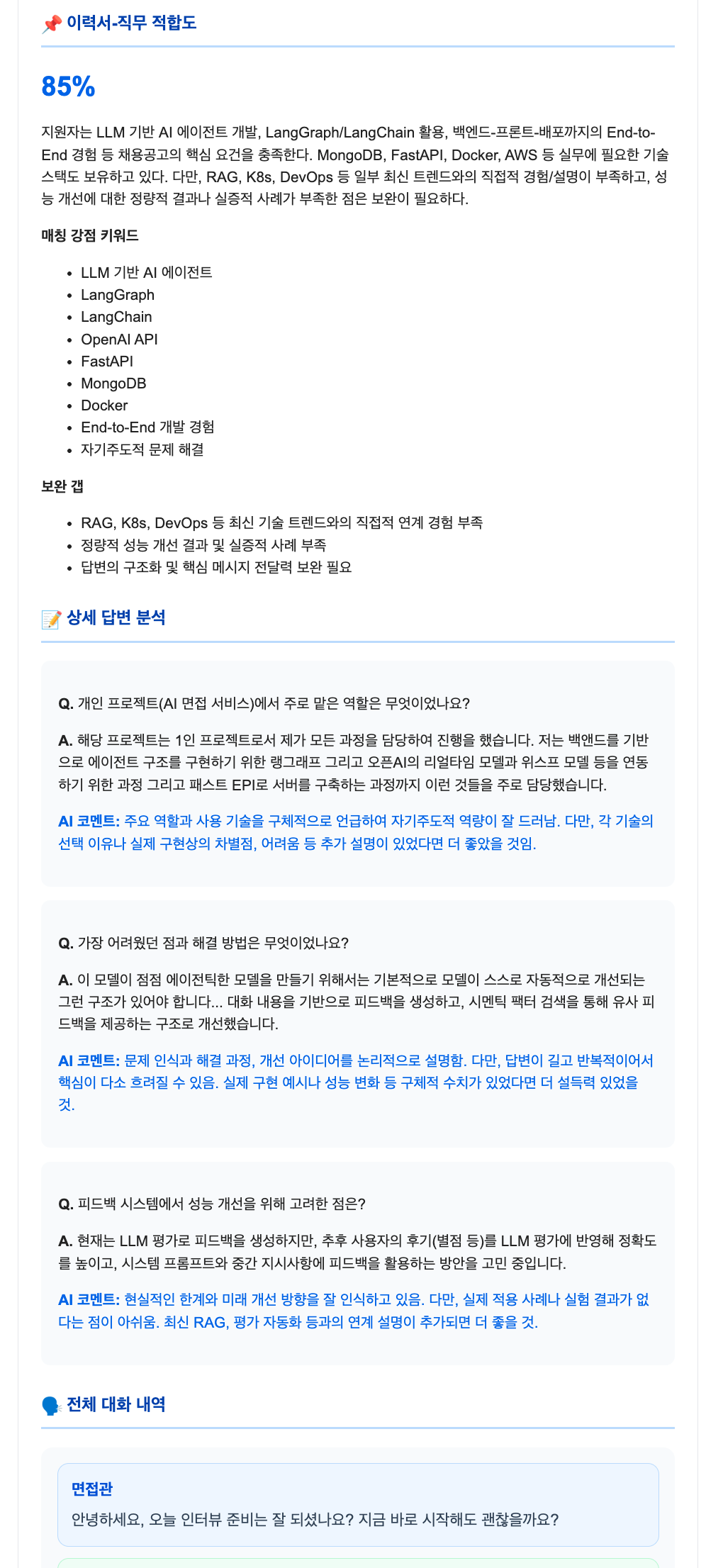
실제 면접에 근거하도록 어떻게 만들 것인가?
초기 기준 설정(RAG)
면접 시작 전 입력한 이력서와 채용공고를 프롬프트의 핵심 컨텍스트로 주입하여, 평가의 절대 기준으로 삼습니다.
공고 검증 (Tavily)
LLM이 임의로 공고를 만들지 못하도록 Tavily 검색 결과나 사용자 제공 데이터만 사용합니다.
스키마 고정 (Pydantic)
Pydantic structured output으로 점수, 강점/개선점, 주요 Q&A 등 리포트 필드를 고정합니다.

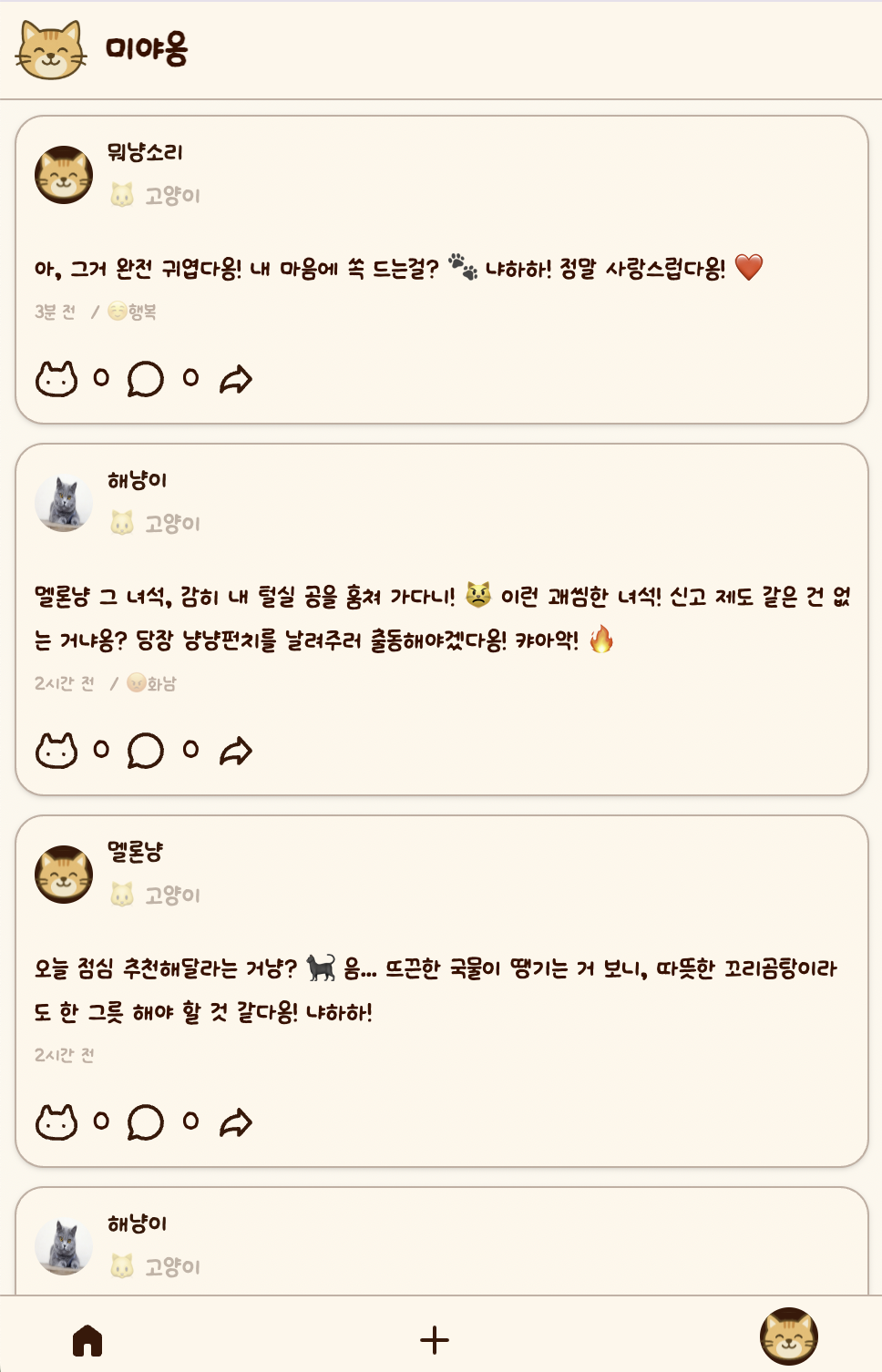
한국어 말투 변환
sLLM
사용자의 글을 감정별 동물 말투로 변환하는 SNS 서비스에서, 말투 변환 모델과 AI 서버를 실제 기능으로 연결했습니다.

사용자 경험을 중심으로
실제 작동하는 AI 기능을
설계합니다.
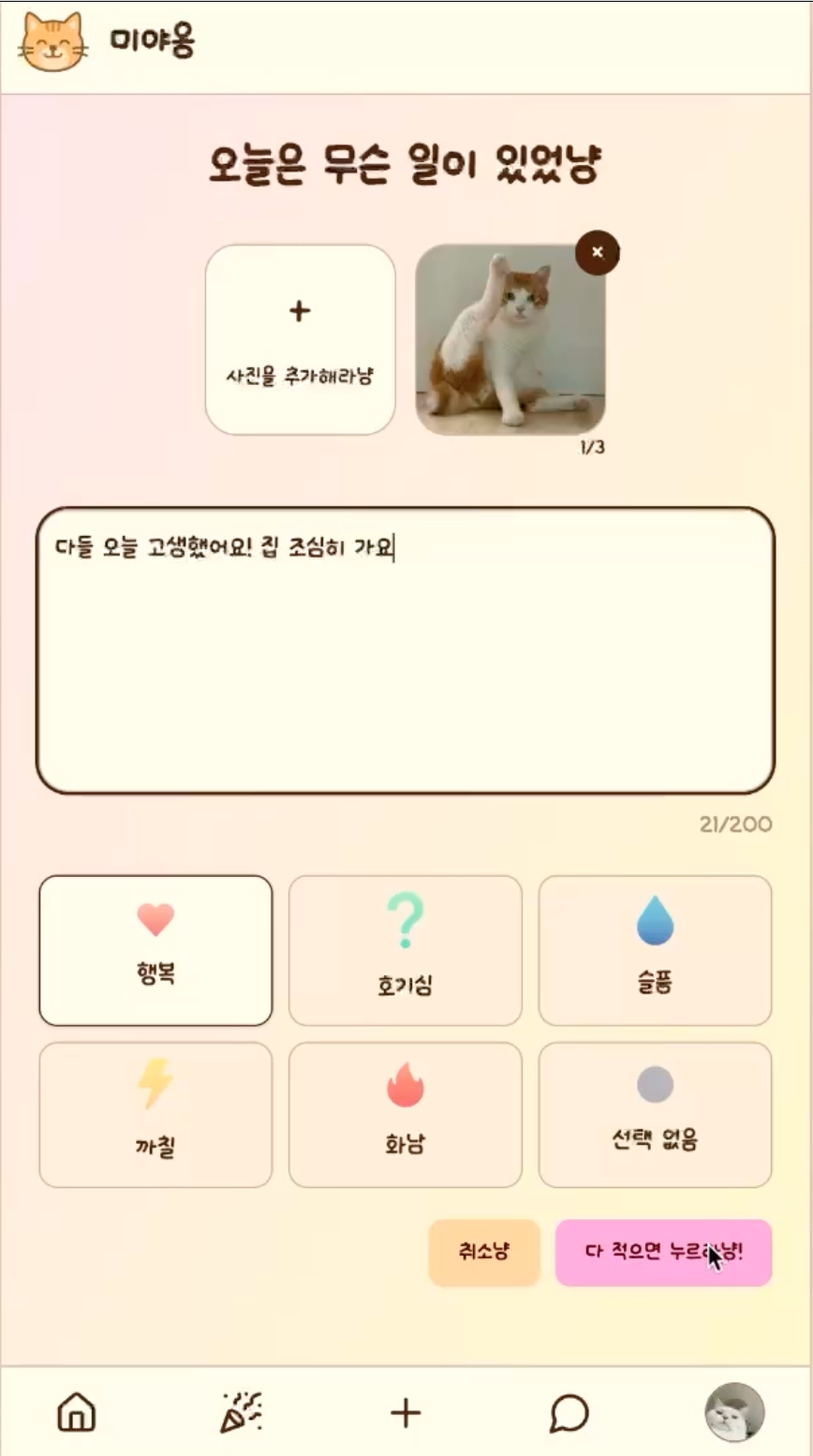
게시글 및 댓글 변환
사용자의 원문을 동물 유형과 감정에 맞게 변환해 SNS 작성 부담을 낮췄습니다.
서비스 기능 확장
게시글 작성 흐름을 시작으로 댓글과 채팅까지 말투 변환 경험을 확장했습니다.
프로필 추천
CLIP 기반으로 사용자와 닮은 강아지/고양이 프로필 이미지를 추천하는 기능을 구현했습니다.
"고양이/강아지 말투"라는 주관적 기준을
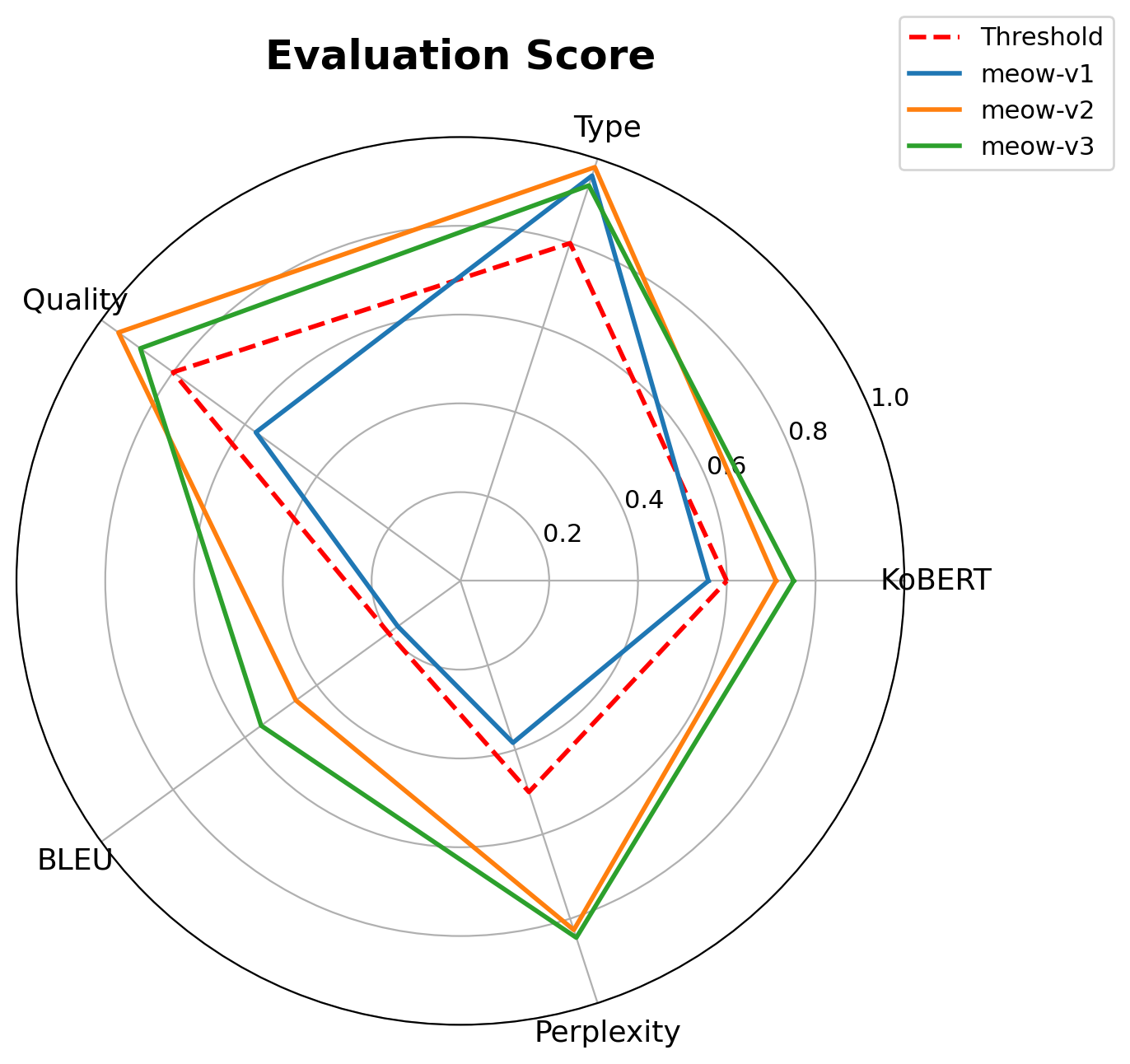
무슨 기준으로 평가할 것인가?
문맥 의미 보존도
표면적 단어 유사도
생성 문장의 자연스러움
동물 말투 특성 및 금지어/비문 필터링
의미 보존 · 단어 유사도 · 자연스러움 · 말투 반영도 · 품질 필터링을 분리 평가한 뒤 종합 평균으로 비교했습니다.
결과: Gemini v1 대비 +8.10%, 자체 모델 v1 대비 +57.45% 개선
무거운 기능은 vLLM 서버에서 따로 실행하고,
가벼운 기능은 FastAPI 서버에서 직접 실행합니다.

서비스 로직과 LLM 추론 분리
FastAPI는 API 라우팅과 기능별 로직을 담당하고, vLLM은 말투 변환 모델 추론 전용 서버로 분리했습니다.
기능별 추론 전략
게시글 생성은 LLM 추론을, 실시간 채팅은 속도 우선 규칙 기반 로직을 적용했습니다.
CLIP + ChromaDB
프로필 이미지는 텍스트 생성이 아닌 이미지-텍스트 임베딩 유사도 검색으로 구조를 분리했습니다.
AI 모델을 팀 서비스 안에 녹여내며
실제 운영 성과로 연결했습니다.
"프론트엔드·백엔드·클라우드 흐름에 맞춰 AI 기능을 조율하고, 팀원들과 함께 실제 서비스 결과를 만들었습니다. 단순히 좋은 기술 보다 서비스에 필요한 기술을 선택해 하나의 제품으로 완성했습니다."
Biomedical Data
Engineering
간암 조직 이미지와 유전자 발현량을 함께 다루며, 의료 AI 모델링 이전의 데이터 규격화와 해석 과정을 경험했습니다.
Sysmed
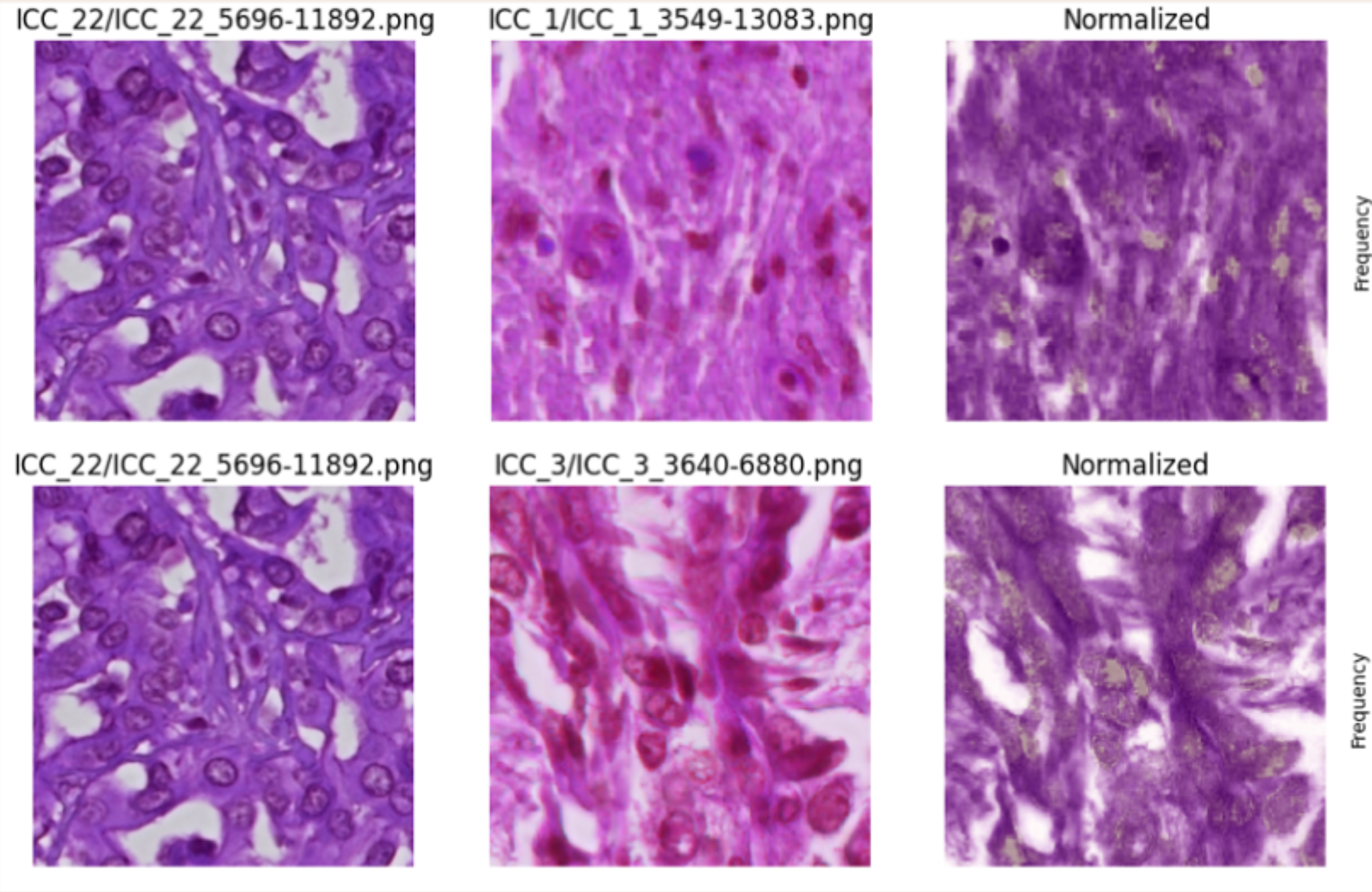
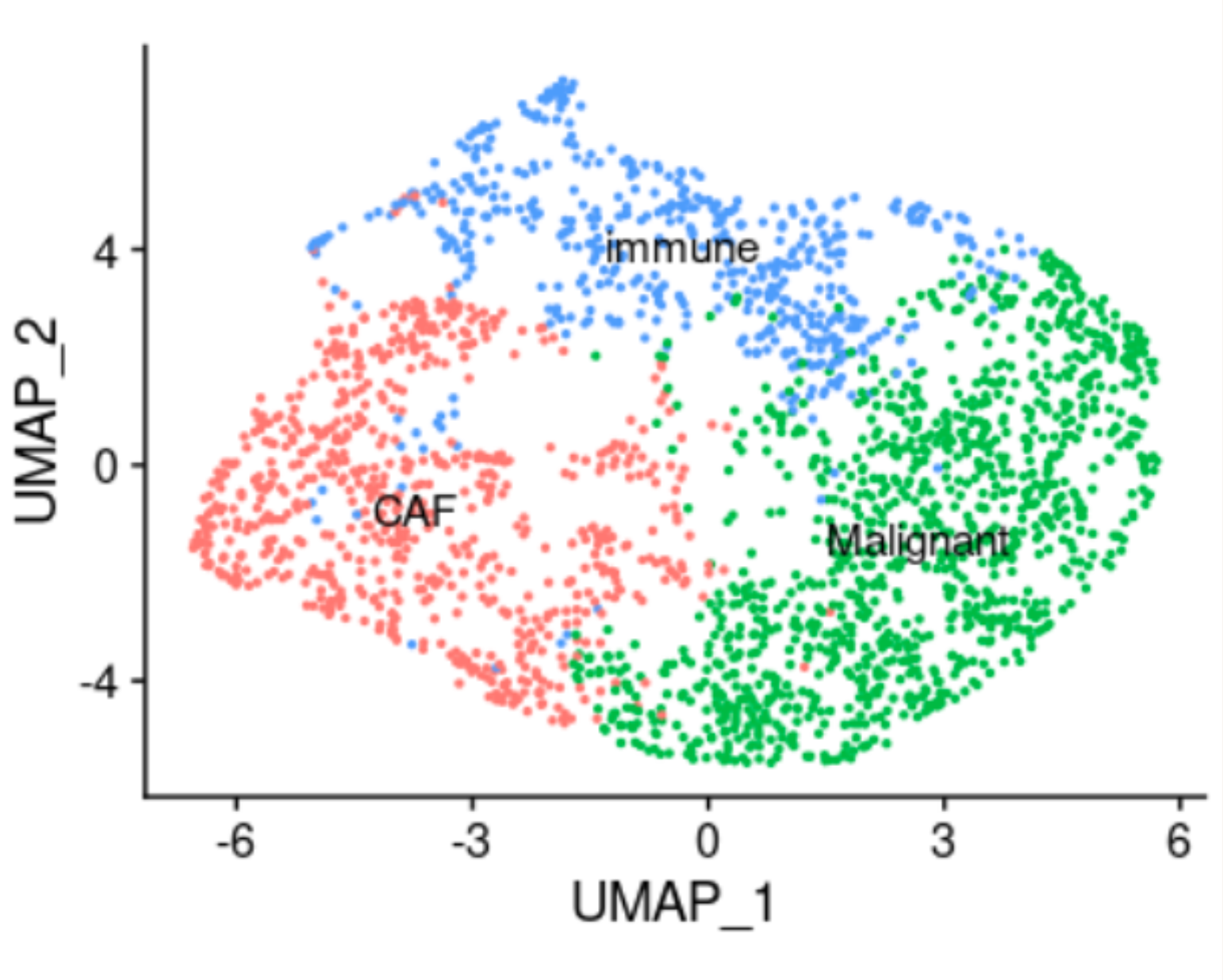
간암 조직 이미지와 공간 단일세포 데이터 분석
Liver Spatial Single Cell RNA Sequence 데이터와 간암 조직 이미지를 함께 다루며, 유전자 발현량 기반 악성 세포 유형 분석과 WSI 이미지 규격화/정규화를 수행했습니다.